From experience we’ve learned that most data science projects are not truly collaborative efforts but only driven by a few key players. Best (public) examples are most open source R and Python packages available on Github. However, collaboration of data science teams can be the determining factor driving innovation in a sustainable way. We highlight some common problems in data science projects and give guidance how collaboration can be improved to facilitate a data-driven transformation in organisations.

Data Science is an interdisciplinary field and requires diverse skill sets to deliver data products. On top of software- and data engineering skills a solid statistical background is needed to reveal interesting patterns and build models. However, we often see a clash of cultures in engineering vs data science/modelling teams. While the former group typically cares more about code quality, testing, and deployment the latter is mostly focused on methodology- and data correctness. Also the development process is quite different: Agile/SCRUM vs. research/hypothesis driven.
Last but not least we see strong opinions and conflicts in data science teams. Most of them are about tools (R vs. Python), methodology (statistical rigorous vs data mining/brute force) and project priorities. Data Science is a very new field and most of these questions depend on the specific problem and respective institutional/company background.
Having a large and diverse group of people working in a relatively new and unstructured environment like Data Science projects can lead to great ideas and innovation - or to utter chaos. The border here is typically very thin and can be positively influenced if you have
- Open team spirit and transparency generating new ideas.
- Teams working efficiently together on projects, reviewing each others ideas which are generated on a continuous basis - with room for failure.
- A well-managed code base which is , maintained and reviewed leading to increased re-usability and positive network effects.
Ingredients leading to adverse effects are just the opposite:
- Team rivalries and politically motivated decision making - fear of failure.
- Teams not communicating with each other, working on redundant projects.
- No managed and reviewed code base consisting of a handful of undocumented scripts/notebooks which leads to no re-usability.
In general the question remains what kind of environment can be created - either from the technical or human resources side - to improve long-lasting positive network effects, or in particular:
- How can code be managed to have positive network effects?
- How can teams efficiently communicate and collaborate together?
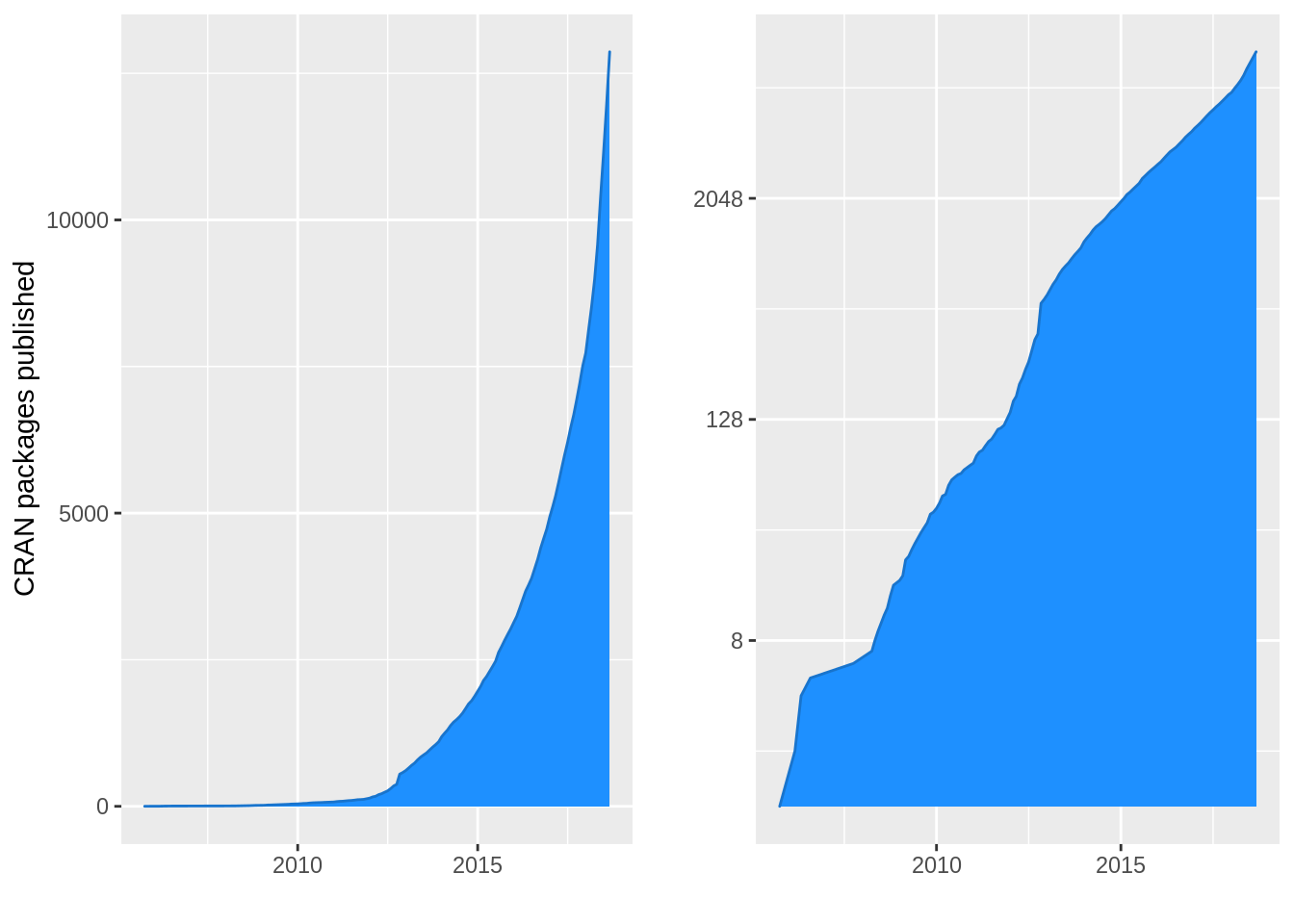
To see the biggest (public) statistical code base in action let’s take a look at the CRAN package repository which has experienced an astonishing growth over the last decade. It hosts well over 10,000 R packages written by authors all over the world. A large part of its success is driven by the simple yet powerful package structure inspired by the Debian Linux package system. Each package is checked for errors by CRAN repository maintainers using R CMD check --as-cran <packagename> and released for all major platforms: Windows, Mac OS and Linux. Even compiled (C++) code within R packages is checked through Address Sanitizers (ASAN) and Undefined Behavior Sanitizers (UBSAN), see also CRAN Package Check Issue Kinds. These and many more procedures lead to a code base which is easier to re-use and maintain, see also Writing R Extensions and Hadley’s more verbose description of the R CMD check workflow.
The implemented function tools:::CRAN_package_db() has been used to extract all relevant package metadata.

R packages can also depend on other packages as defined in the package DESCRIPTION file through Imports or Depends. This makes proper check procedures and interfaces between packages even more important since an error in one dependency can affect a large number of packages. The picture above shows the dependency graph of the most downloaded R packages on CRAN.
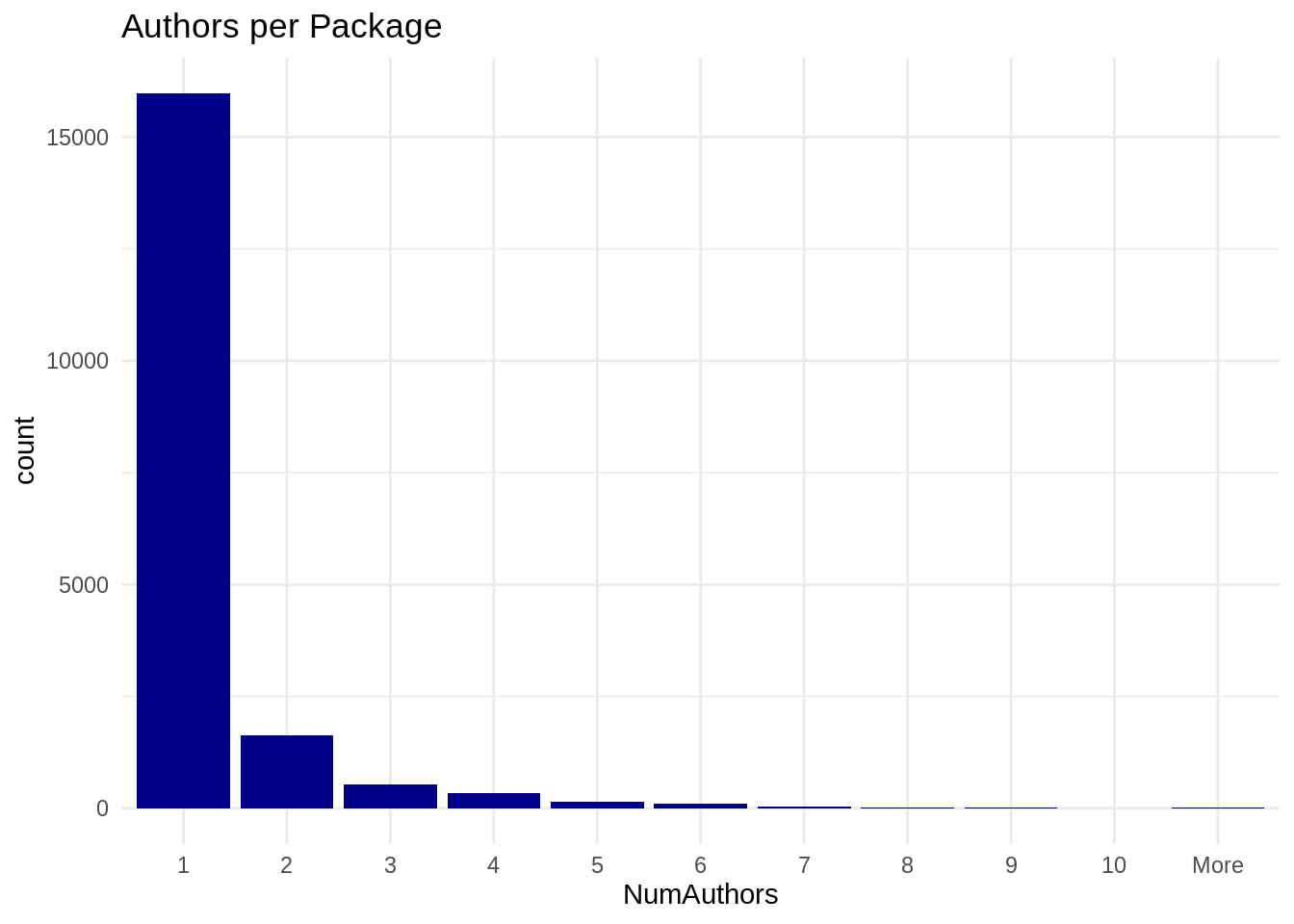
Interestingly, we observe that the vast majority of packages is developed by only one single author. The reasons for this could be manifold including the R package structure itself to be most suitable for single writers, scientific studies conducted by only few scientists and general social behavior of R-programmers.
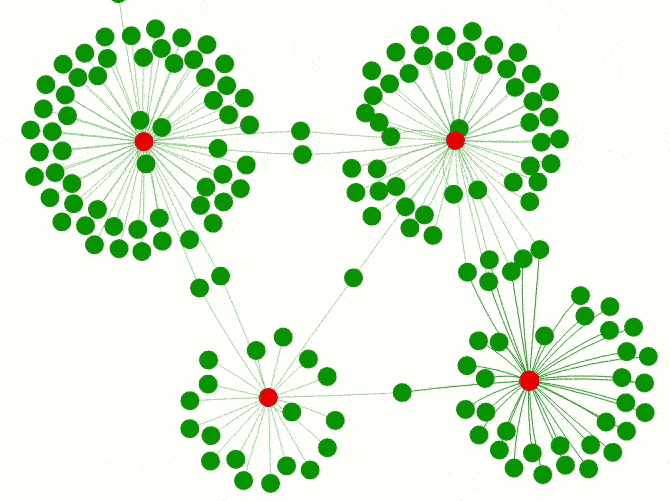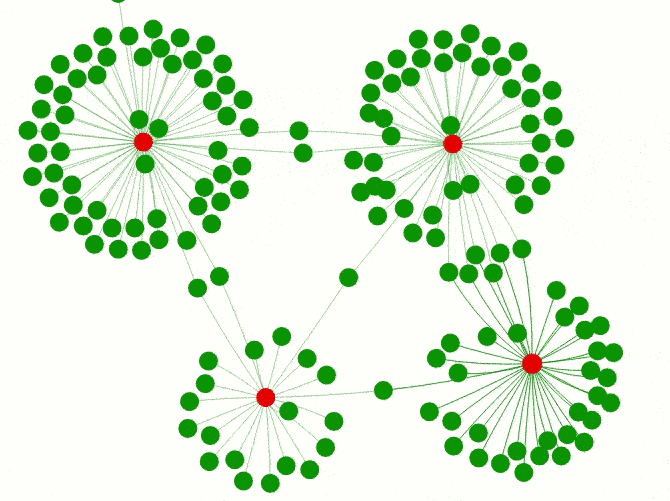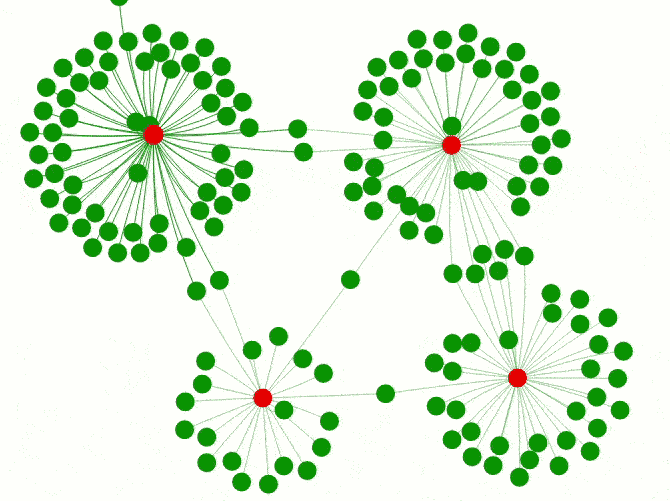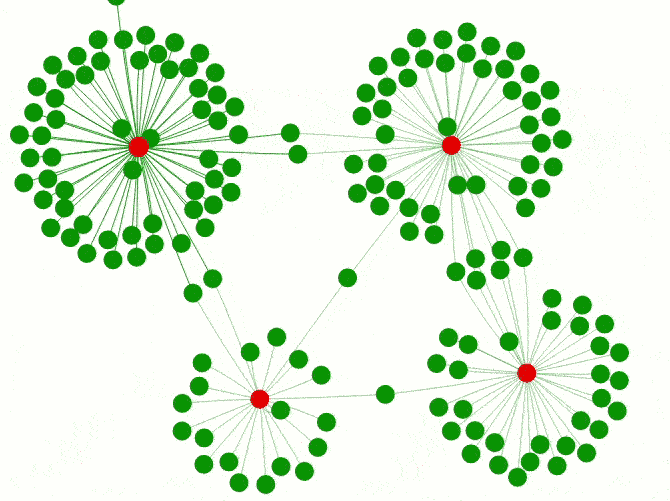
However, the lack of communication between package authors and a clear overview of which packages actually exist can lead to redundant developments. While a wider variety of packages for different model implementations can be helpful it does not make much sense for infrastructure packages. A good example is the package universe dealing with Excel files including xlsx, XLConnect, gdata, openxlsx and readxl. The graph below shows how these packages create different clusters of reverse dependencies. Some of them even wrap functionalities of different Excel packages and act as connectors/wrappers like DataLoader or ImportExport.
Last but not least there exist very basic barriers for authors not collaborating with each other: EGO. Not satisfied with most existing packages1 dealing with HDF52 files to store high-frequency tick-data in a high-performance, language independent format I decided to create a new one: h5 (deprecated but still on Github and CRAN).
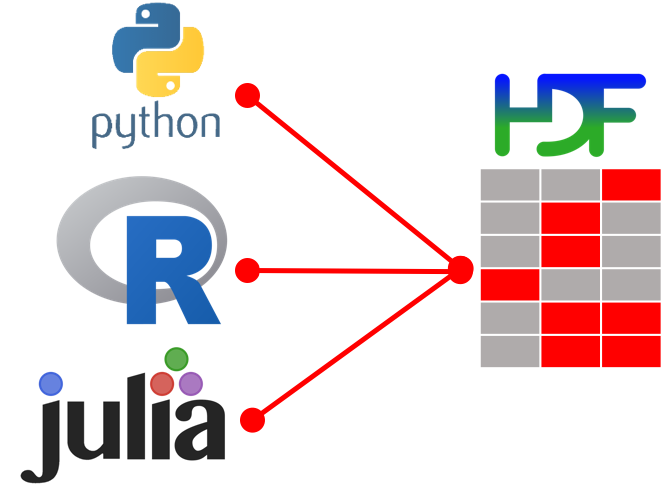
After having spent quite some time developing a h5 which was presented at R/Finance 2016 I received an E-mail from Holger which stated that he also developed a package to tackle the problem:
On June 21, 2016 Holger wrote:
… my name is Holger Hoefling, I have developed a new version of a wrapper library for hdf5 (R6 Classes, almost all function calls wrapped, full support for all datatypes including tables etc) …
Having overcome my own EGO barrier (which was quite hard) and after inspecting his package we agreed to work together on one HDF5 package and merge codebases (which sounds easier than it was) to
- Maintain high-level interface and test cases from h5
- Get low-level HDF5 support within R

The joys of collaboration (after overcoming psychological barriers) are great and typically lead to longer-term projects, regular code-reviews and in my case a merged package which is of higher quality than each of the previous ones.
My recommendations are thus as follows:
Q: How can code be managed to have positive network effects? y
- Put it into re-usable package.
- Continuous code-reviews and tests.
- Use a transparent code platform to inspect source (like Github).
Q: How can teams efficiently communicate and collaborate together?
- Have the right tools and mindset in place.
- Incentivize collaborative efforts.
- Accept unexpected hypotheses and failures
- Open mindedness.

